从碎片到体系:我的AI技术生态认知复盘
前言: 从初次尝试Vibe Coding至今,靠AI完成开发从0到1的可商用APP前后端,以及Text_To_SQL的BI Agent完成,接近两三个月时间,在此用自己的理解,和较直白易懂的表达来总结一下这段时间所学,以及对整个AI生态的理解变化,也以此加强一下自己的所学知识。
费曼效应:是指一种通过主动输出、通俗化表达来深化认知理解的现象。即当一个人尝试用最简单、直白的语言将某个复杂概念解释给他人(或假想的初学者)听时,会触发大脑的深度加工机制,从而迅速暴露知识盲区、重构逻辑框架,并最终实现对知识的透彻掌握。
第一阶段:初识尝试Vibe Coding
Cursor:第一次放手给AI直接动我的项目代码
我的AI之旅始于Cursor。第一次体验Vibe Coding的那种感觉至今难忘,在26年3月左右,我还在万科泊寓的时候,第一次用Cursor打开了我负责的项目,并全程通过对话让其完成了我当时的一个小需求,当时让我惊艳的并非他可以自己动手写,而是其项目理解能力,从我的项目阅读了正确的文件并且做出了正确的改动。
Claude Code:一切的起点
第一次体验过Vibe Coding之后,立马激起了我对AI的学习激情,通过当时我们CTO曾师傅的建议,开始接触学习业界公认最强的通用Agent(先这么定义它?),也就是Claude Code,然后开始试图用cc来开发一个完整的项目,于是很快就遇到了Vibe Coding路上的第一个问题:面对大的项目的时候,不知道该怎么上手,一个点一个点的对话,用于开发冗余代码,且AI会进行很多重复的工作。
SDD: Spec-Driven Development,即规范驱动开发
为了解决上述困扰,接触了Speckit这个工具,在传统的Vibe Coding中,主要流程基本就是 开始 -> 编写prompt -> 检查 -> 完成或者修改(部分可用)或者整个返工,流程不可控,且可能由于上下文窗口不足引发的幻觉代码,看似没问题一跑就出错,Speckit的工作流则是:
开始
↓
建立项目宪法(/speckit constitution)
↓
编写功能规范(/speckit specify)
↓
需求澄清(/speckit cleaify,这一步如果发现问题会循环进行直到没有疑问)
↓
生成计划(/speckit plan)
↓
拆分任务(/speckit tasks)
↓
一致性分析(/speckit analyz,这一步如果发现有冲突,会修改Plan)
↓
自动实施(/speckit implement)
对比传统的Vibe Coding,使用SDD的工作流的优势很明显:
优势
- 更可靠的代码,极大降低返工率
- 通过率提高带来的token成本降低
但是通过实操也发现了这个工作流的问题,也很明显:
缺点
- 太重了。任何问题,使用这个工作流来处理,都一定要经过上面的所有步骤,并且这个工具会默认使用TDD,也就是测试驱动开发,所有步骤实现过后,都会走测试,因此会导致一些简单工作复杂化,且耗时大幅增加。
- 不能自动拆分任务。工具划分出的所有任务,例如phase1 - phase4,他不会开启subagent去处理,全在一个会话中,因此特别容易爆上下文,我当时使用的是Deepseek V3.2的模型(4月初,Deepseek V4 Pro还未发布的时候,因为是学习阶段,所以还没上Opus等顶尖模型),而ds 3.2的版本上下文窗口是128k,通常在Plan阶段,就会报400的错误,也就是上下文窗口不足,还没开始写代码上下文就炸了。
- 第二个问题的解决方案就是再进一步细化目标,把一个更小的目标交给Speckit,但是这样上下文是够了,但是与使用这个工具的初衷背道而驰了,本来就是为了工程化任务准备的工作流,用来实现一些小的点,肯定不合适。
随后的一段时间,在通过Claude Code的Plan Mode和Speckit的混合使用下,开发完成了我的第一个完整可用的APP(包括APP本体、后端以及数据库),得出了一些经验:
总结
- 上下文管理: 有的模型比如(Deepseek V3.2),当上下文窗口不足的时候,会直接报400错误,而有的模型校验没有这么严格,会采取相对柔性的处理方式,继续返回,但是这种情况,必然会加重AI的幻觉,产出一些不可控的代码,因此上下文管理十分必要,可以通过
/context来查看当前上下文窗口使用情况,在80%左右,可使用cc提供的/compact来进行上下文压缩(摘要),需要注意的是,压缩次数越多丢失的信息越多,所以核心的方案是开发者合理拆分任务,用不同的会话处理不同的任务,善用/clear. - Claude.md: 从今天回头看,随着AI能力的飞速发展,当国内开发全面进入Vibe Coding的时候,由于生产效率的飞跃,必然迎来需求大爆发,从Anthropic内部的数据就能看出,整体代码产出提高了200%,那么在开发新项目的时候,我认为第一个编写的一定是Claude.md文件,那么需要包括但不限于以下的理解:
- 一个项目可有多个Claude.md文件,和传统项目的同名配置文件一样,作用于最小的优先级越高,通常项目级别的Claude.md文档中规定一些通用的规则。
- Claude.md文件最好控制在200行内。
- 一些常识性的规则不需要显示声明,比如方法名要见名知意、或者描述一些通用的目录是干嘛的等等均不需要提及。
- 使用渐进式披露技巧:200行的约束是针对单个文件,像我在我的后端项目中的Claude.md文件中,就加入了一条,服务器信息见SERVER.md,把所有服务器的情况,包括ip地址,Nginx配置信息等等信息都写入这个文件,则可以省出一大部分配置位置。
- 一定要写的:
- 如果项目有架构要求需要声明(比如我的PigIcream项目是严格遵循MVVM架构)。
- 项目红线:比如我开发的TEXT_TO_SQL的BI Agent,则需要声明哪些表可查询,并限制只能使用SELECT语句,其他操作均不允许。
- 技术栈和依赖限制,可以提及一下,一般就占用两三行的位置,可以约束AI不导入冗余的依赖,或者导致一些不必要的依赖冲突。
- 个人偏好方面:如注释使用中文等等。
第二阶段:知识碎片轰炸
在使用Claude Code完成一个可商用项目之后,自然而然的,企图学习更多的AI相关的技术,于是就到了我最迷茫的一个阶段,大量的专业名词扑面而来,RAG、微调(Fine-Tune)、Function Calling、MCP、Agent、Transformer、注意力、Langchain、LangGraph、提示词工程、上下文工程、Harness Engineering、AGI、OpenClaw、Hermes、Skill...
第三阶段:实现第一个Agent,思维跃迁
和大学的时候学习算法一样,在解决碎片化知识轰炸问题的时候,有两个解法,一个是直接嵌套for,暴力解决,直接每个知识点都体系化的学习一遍,自然的,时间复杂度就是O(n²);而学习最好的方法,无非就是在实战中进行,于是有了我开发的第一个Agent,也是这个项目,把所有学习到的知识都串联了起来,接下来我会把我对这一系列名词,做出我自己通俗化的理解叙述。
什么是AI Agent?
官方一点的定义是一个能完成以下动作的智能体:
- 感知环境(通过Observation)
- 制定计划(通过Planning)
- 执行动作(通过Action)
- 反思结果(通过Reflection)
而我更喜欢的说法是一个Antropic和CodeX等AI一线大厂公认的公式:
Agent = Harness + Model
Langchain && LangGraph
对于老开发来说,学习Langchain毫无门槛,这就是一个开发Agent的框架,一眼看过去,尽是封装。
- 首先就是对各个模型厂商api接口的封装:包括Model、Tools、Memory等等,把接口需要的参数,封装成一个个的对象,然后构建对象发起请求,并且很好的适配了各种厂商的接口,抹平了不同厂商之间的接口差异,可以让一套代码,几乎无改动的跑在所有模型上面。
- 执行逻辑的编排:Langchain提供全场景编排,见名知意,chain即链式编排,graph则是一个有向图,两者提供不同的做工作编排支撑。这个工作流不仅仅是在Agent应用层面,也支持包括RAG、Memory等模型层面的编排。
- 还提供了LangSmith,一个可观测性平台,它提供了链路追踪(Tracing)、性能评估、Prompt 测试等功能,帮助开发者看清每一次 LLM 调用的输入输出细节,从而排查错误并持续优化。
- Middleware,提供了很多中间件,可以实现各种增强,比如Azure AI Content Safety,可以在给大模型发出请求前,先分析提示词,防止提示词注入等风险;同时可以通过langGraph的有向图,来实现Agent的自进化,最简单的自进化实现方式就是定义一个包含"生成节点(Generator)"和"反思/批评节点(Critic/Evaluator)"的工作流。初始生成后,反思器会从内容质量等维度提供改进意见,随后生成器根据反馈进行迭代修订(例如默认最多循环3轮),直到达到满意状态或终止条件。
Function Calling
Model是Agent的大脑,而LLM实际上玩的是一个token推理游戏,无法推测出未知的信息,因此,需要为其提供一些模型之外的能力,而这一切的起源, 就是OpenAI,最初OpenAI对外的api中,有这样一个参数:
# 一个典型的Function Calling示例
functions = [
{
"name": "get_weather",
"description": "获取指定城市的天气信息",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
]这个格式也被后续几乎所有模型厂商延用了下来(包括不限于Deepseek、Qwen等),不过这些api差异不需要开发关注,使用Langchain开发即可无视模型厂商间的差异。
另外的,也可以直接通过提示词完成Function Calling,在提示词中,告诉大模型可使用的工具列表,需要什么类型的参数格式,返回什么类型的响应即可。
MCP协议
Function Calling给了大模型调用工具的能力,但是对于一些通用的、或者某方面特别优秀的复杂函数,如果在不同的Agent之间,希望复用,则出现了阻碍,因此,Anthropic提出了MCP协议(Model Context Protocol)。
定义 官方文档
MCP (Model Context Protocol) is an open-source standard for connecting AI applications to external systems.
即:MCP(模型上下文协议)是一种用于将 AI 应用程序连接到外部系统的开源标准。
这里一些官方文档中有的内容就不再赘述了,简单说一下使用需要注意的地方:
掌握技术最好的方法就是上手做一下:附上Python的Quick Example,主要有以下几点:
-
快速定义MCP服务器,@mcp.tool()、@mcp.resource()、@mcp.prompt()以及资源订阅等方法的使用。
-
MCP 是一种有状态协议这就需要生命周期管理。使用FastMCP构建MCP Server,并管理它的生命周期。
-
提供的tool方法参数列表可以定义Context类型的参数,可以直接获取调用方的上下文信息,注:这里的Context并非调用方传统意义上的上下文,此处的Context参数的功能详见文档。
-
MCP 客户端(Client):
-
启动并连接 MCP 服务器
server_params = StdioServerParameters( command="uv", args=["run", "server", "completion", "stdio"], ) async with stdio_client(server_params) as (read, write): async with ClientSession(read, write) as session: await session.initialize() -
获取并美化显示tools
async def display_tools(session: ClientSession): tools_response = await session.list_tools() for tool in tools_response.tools: display_name = get_display_name(tool) print(f"Tool: {display_name}") -
获取并美化显示Resources
async def display_resources(session: ClientSession): resources_response = await session.list_resources() # ... 遍历打印资源和资源模板 -
补全、诱导、采样...等更多详见文档。
微调(Fine-tuning)
这个概念是与模型本身的能力紧密联系的,是把模型在特定的领域上继续训练,非常适合让AI掌握特定的语气(风格)、输出格式等,因为是训练得模型本身的能力。
- 所以优势非常明显:
- 1、响应速度快,不需要像RAG一样做额外的检索行为;
- 2、深层推理能力更强,对于需要多源信息融合、复杂逻辑推断的任务,微调能让模型内化分析模式,给出更深刻的回答。
- 至于缺点在我看来,主要是两点:
- 1、成本问题,因为是继续训练模型,所以算力成本不可忽略;
- 2、耗时问题,对于短期内可能改变的信息不能使用微调,否则可能出现微调还没结束,相关信息就已经失效了。
RAG (Retrieval-Augmented Generation,检索增强生成)
对比微调,RAG操作就显得轻量级一些。RAG就可以简单的理解为把需要的外界知识(当前模型还没有掌握的),向量化并存进向量数据库,当用户提问时,系统会先去数据库里"检索"出相关的几页资料,再把这些资料连同问题一起喂给大模型,让它基于这些真实信息总结生成答案。
- 所以可以简单的总结出RAG的优势:
- 秒级更新:因为它不像微调需要重新训练,只需要替换对应的外接知识库就行了。
- 可溯源,幻觉低:所有结论可以追溯到知识库中对应条目。
- 权限控制灵活:这一点可以通过针对不同用户,开放不同的知识库访问权限来控制。
- 缺点:
- 上下文瓶颈:因为每次请求都会带上知识库中检索出的信息,自然就更耗token,同时响应速度会相对变慢。
- 检索噪声干扰:对向量切分和匹配方式都有较大考验,否则携带与用户问题相关性不大的知识,反而会误导大模型产生预期外的结果。
总结一句就是生产环境中通常混搭使用,业界有一个基本的共识:RAG 负责事实,微调负责风格。
Agent
可以说理解了Agent,所有零散的AI相关概念,就可以串起来了。
我感觉目前对于Agent,最好的总结大概是以下两条:
-
Agent是一个能感知环境、制定计划、做出行动、检查反馈的智能体。Agent Loop: 思考 -> 行动 -> 观察。
-
Agent = Model + Harness
Tip: 你不知道的 Agent:原理、架构与工程实践 这里推荐一篇X上很好的博客;
针对第一条,可能会有一个疑惑,**那么Agent和workflow的区别是什么?**在上面那篇博客中有提到,简单说一下:
Anthropic 对这两类系统有一个直接区分:执行路径由代码预先写死的是 Workflow,由 LLM 动态决定下一步的是 Agent,核心区别在于控制权掌握在谁手里,现实中很多标着 Agent 的产品,深入看其实更接近 Workflow,不过两者本身并无高下之分,真正重要的是给任务找到更适合的解决方案。
理解了Agent是什么,那么基本就可以把所有AI生态相关的技术,分为两类了,一类是模型相关的技术,一类是应用相关的技术。那么这些技术是做什么的就十分清晰了。
至于上文中公式中提到的Harness,我在后文中会讲到。在那之前,先说说另外两个工程,提示词工程(Prompt Engineering)和上下文工程(Context Engineering)。
提示词工程(Prompt Engineering)
定义:根据 《Prompt Engineering Guide》 这份指南中对提示工程的解释,提示工程(Prompt Engineering) 是一门关注于 提示词(Prompt) 的开发和优化的学科,能够帮助用户将大模型用于各种应用场景和研究领域,比如我们可以利用提示工程来提升大模型处理复杂任务的能力(如问答和算术推理);或者实现大模型与其他生态工具的对接。
提示词由下面的一个或多个要素组成:
- 指令(Instruction):给模型下达指令,或者描述要执行的任务;
- 上下文(Context):给模型提供额外的上下文信息,引导模型更好地响应;
- 输入数据(Input Data):用户输入的内容或问题;
- 输出指示(Output Indicator):指定输出的类型或格式;
提示词所需的格式取决于你完成的任务类型,并非所有以上要素都是必须的。提示词工程师一门经验科学,因此它需要大量的实验和测试。
技巧:
- 从简单开始,通过真实实验和测试,然后不断的添加更多的元素和上下文。
- 减少不精确的描述,确保提示词是明确、具体、尽可能详细的。
- 角色扮演。可以在系统提示词中,给大模型明确其身份和意图。
- 少样本提示。可以给AI提供回答的例子供AI学习。
上下文工程(Context Engineering)
- 【Lanchain】Context Engineering(lanchain)
- Effective context engineering for AI agents(Anthropic)
1.Anthropic认为,上下文工程是提示词工程的自然延伸。上下文工程指的是在 LLM 推理过程中,用于管理和维护最佳token集的一系列策略,包括提示词之外可能出现的所有其他信息。
Claude的上下文工程实现是三层记忆架构:
- 短期记忆(当前对话)
- 中期记忆(智能压缩)
- 长期记忆(CLAUDE.md 项目知识库)
At Anthropic, we view context engineering as the natural progression of prompt engineering. Prompt engineering refers to methods for writing and organizing LLM instructions for optimal outcomes (see our docs for an overview and useful prompt engineering strategies). Context engineering refers to the set of strategies for curating and maintaining the optimal set of tokens (information) during LLM inference, including all the other information that may land there outside of the prompts.
2.LangChain认为:上下文工程是一门艺术和科学,它旨在Agent轨迹的每一步都为其上下文窗口填充恰当的信息。并且提到了上下文工程的一些常用策略——**编写、选择、压缩和隔离。**并在文中提到了 LangGraph 如何支持这些策略。
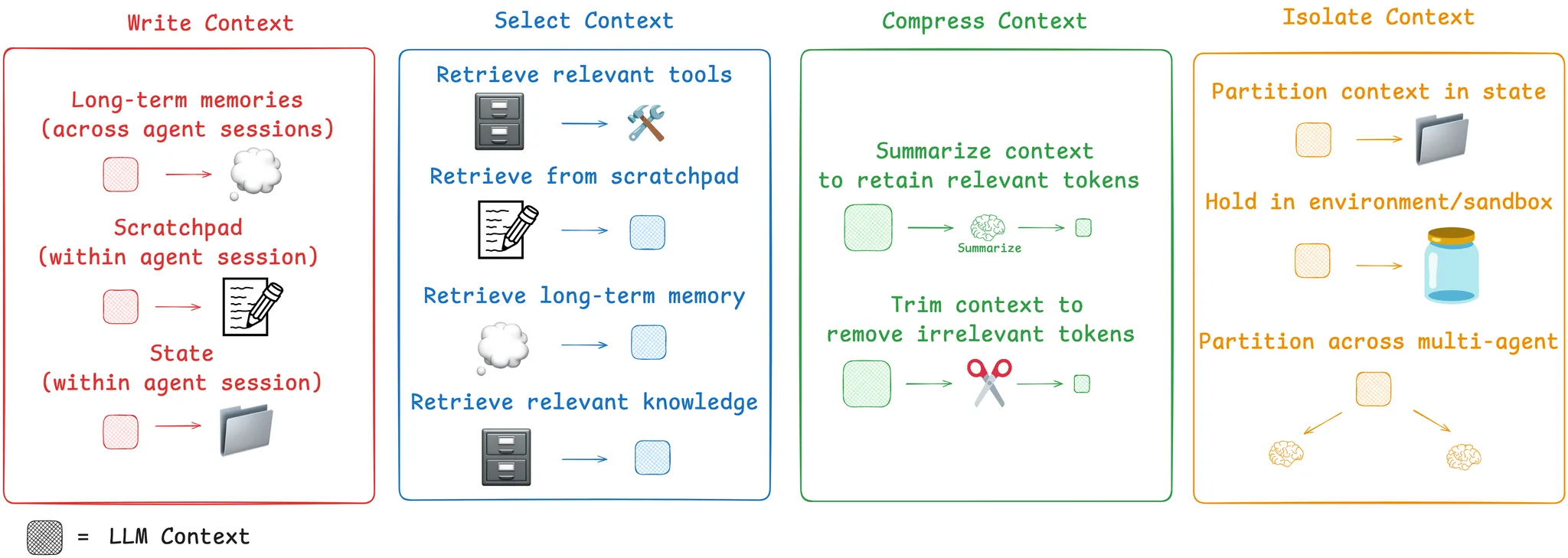
Agents need context to perform tasks. Context engineering is the art and science of filling the context window with just the right information at each step of an agent's trajectory. In this post, we break down some common strategies — write, select, compress, and isolate — for context engineering by reviewing various popular agents and papers. We then explain how LangGraph is designed to support them!
Agent Skills
先附上Anthropic的文章:
https://claude.com/blog/equipping-agents-for-the-real-world-with-agent-skills
Claude is powerful, but real work requires procedural knowledge and organizational context. Introducing Agent Skills, a new way to build specialized agents using files and folders.
Agent Skills: organized folders of instructions, scripts, and resources that agents can discover and load dynamically to perform better at specific tasks. Skills extend Claude's capabilities by packaging your expertise into composable resources for Claude, transforming general-purpose agents into specialized agents that fit your needs.
技能是一个目录,其中包含一个 SKILL.md 文件,该文件包含组织有序的文件夹,其中包含指令、脚本和资源,这些指令、脚本和资源为Agents提供额外的功能。
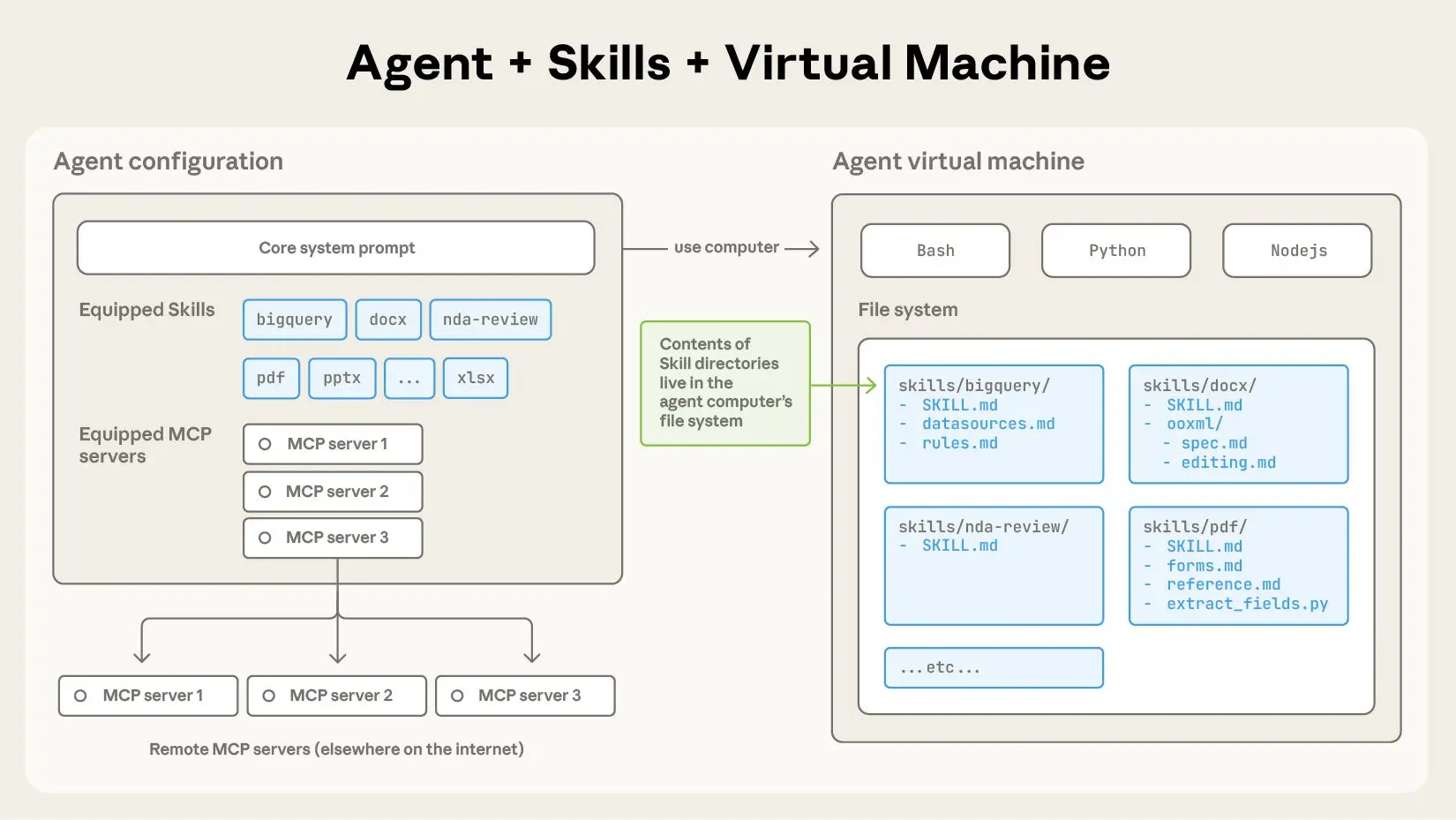
Agent Skills: 一个包含指令、脚本和资源的有序文件夹。Agent可以动态发现并加载这些文件夹,从而更好地完成特定任务。Skills 通过将您的专业知识打包成可组合的资源供 Claude 使用,扩展了 Claude 的功能,将通用Agents转变为满足您需求的专用Agents。
而Skill可能包含过多的上下文等信息,无法放入单个配置文件中SKILL.md,因此,也会使用和CLAUDE.md中相同的技巧,渐进式披露,reference.md and forms.md。
而这个技术概念诞生的原因,大致有以下几点:
-
上下文污染(Context Pollution)
- 早期做法是把所有规则、流程、工具说明都塞进 System Prompt,导致 Prompt 动辄数万 Token。这不仅成本高昂,还会让模型注意力分散、输出质量下降。Skill 通过渐进式披露机制,只在需要时才加载相关内容,实测可将上下文 Token 消耗降低 60%–80%。
-
工具调用不稳定
- 当 Tools 数量增多后,Agent 会出现"乱调用、漏调用、参数错、顺序不稳、失败不重试"等问题。Skill 将"怎么用工具把事做对"的套路(选择条件、步骤、校验、兜底)沉淀为可复用模块,显著降低了随机性。
-
提示词维护困难
- 随着业务逻辑越来越复杂,Prompt 逐渐变成"提示垃圾场(prompt sludge)"——改一个流程就要动整段大提示,版本不可控,复制粘贴导致不同项目之间不一致,排障极其困难。Skill 将这些配置信息统一写入标准化文件,支持版本管理、灰度发布和回滚。
-
复用性极差
- 传统做法中,复杂的业务逻辑被硬编码在对话历史或单个 Prompt 中,难以跨项目、跨团队迁移。Skill 以文件夹形式存在,可以通过 Git 管理、团队共享、跨平台复用(Claude、OpenAI Codex、GitHub Copilot、Cursor、VS Code 等 26+ 平台均已支持)。
-
多 Agent 架构过于复杂
- Multi-Agent 方案虽然功能强大,但编排逻辑复杂、上下文切换成本高、信息传递容易失真。Skill 提供了一种更轻量的替代方案——不换 Agent,只换"角色+手册",用单个 Agent + 多个 Skill 的组合,拿到多 Agent 的分工好处,却没有额外的工程负担。
总的来说,Agent Skill是一种可复用的任务能力封装单元。简单来说,一个 Skill 就是一个打包好的"技能包"文件夹。
Harness Engineering
OpenAI在2026年2月11日发布的文章 https://openai.com/zh-Hans-CN/index/harness-engineering/
定义:Harness Engineering 是 2026 年 AI 工程领域最核心的新范式,它解决的是一个根本性问题:当 AI Agent 开始进入真实工程项目后,我们如何让它稳定、可控、可验证地完成任务?
它的核心理念可以用一句话概括:
每当发现 AI Agent 犯错时,我们构建一套工程化方案,确保它在未来不会重蹈覆辙。
这个定义最早由 HashiCorp 联合创始人 Mitchell Hashimoto 在 2026 年 2 月提出,六天后 OpenAI 在百万行代码实验报告中正式采用这一术语,随后 Martin Fowler 撰文深度解析,一个月内成为行业共识。
而这也是截止今日,AI领域正在进行的阶段,可以理解为是Prompt Engineering -> Context Engineering的自然延伸。从上文的公式Agent = Model + Harness可以视为:Harness = Agent - Model,也就是一个Agent中,除了大模型的部分,都可以视为Harness的一部分。
第四阶段:构建完整的AI生态认知体系
AI生态的四层架构
经过两年的探索,我最终梳理出了AI生态的完整架构:
1. 基础层:大模型平台
- 角色:提供核心的自然语言理解和生成能力
- 代表:Claude、GPT、Deepseek等
- 关键指标:上下文长度、推理速度、多模态支持
2. 工具层:能力扩展机制
- Function Calling:连接外部API
- RAG:增强知识检索
- 插件系统:扩展特定领域能力
3. 框架层:智能体开发平台
- LangChain:最流行的开发框架
- LlamaIndex:专注数据连接
- AutoGen:多智能体协作
- LangGraph:复杂流程编排
4. 应用层:最终用户价值
- 个人助手:提升个体生产力
- 企业应用:优化业务流程
- 开发工具:改变软件开发范式
End - 复盘总结
我的学习方法论
我总结了四个有效的学习策略:
1. 实操永远是最好的老师
每个新技术点都通过实际项目来验证,而不是停留在理论层面,可以是在真实项目中使用也可以是自己的Test Project,但是一定要动手去做。
2. 对比分析法 && 认知深入
将新技术与已有的知识体系进行对比,寻找共性和差异,加深理解,知道这个技术是干嘛的,是主要负责哪一块的。
3. 持续学习
保持开放心态,保持对AI生态的关注,不一定要每个新技术都上手,但是需要大概知道它的存在,什么火了就上手实操一下。
4. 输出倒逼输入
根据费曼效应,通过写作、分享来检验和深化自己的理解。
结尾贴个我找到的宝藏博主的文章: 近年 AI 应用技术串讲与优质文档分享|Agent、Skill、OpenClaw、Harness……